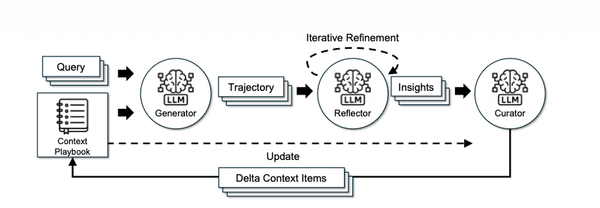
I keep coming back to this one question lately: whats actually the most impactful thing you can do to make an LLM system better? Fine-tune it? Use a bigger model? Throw more compute at inference?
Turns out, according to a ICLR 2026 paper from Stanford and SambaNova, the answer might