Context Matters: The Biggest Lesson from ACE (ICLR 2026)

I keep coming back to this one question lately: whats actually the most impactful thing you can do to make an LLM system better? Fine-tune it? Use a bigger model? Throw more compute at inference?
Turns out, according to a ICLR 2026 paper from Stanford and SambaNova, the answer might be none of the above. The paper is called "Agentic Context Engineering" (or ACE for short), and honestly its one of the more suprising results I've seen in a while. The core idea is deceptively simple but the implications are kind of huge.
The Setup: Why Context Matters
So heres the situation. You have an LLM. You want it to do something specific — maybe act as an agent that interacts with APIs, or do financial analysis on business reports. The traditional playbook says: fine tune the model on your domain data. Or if your fancy, use RLHF or some form of preference optimization.
But theres a whole other approach thats been gaining traction, which the authors call "context adaptation." Instead of changing the models weights, you change what goes into the models input. System prompts, few-shot examples, instructions, strategies, domain-specific tips — all of that stuff that sits in the context window before your actual query.
This isnt new obviously. We've all written system prompts. We've all done few-shot prompting. But what ACE does is take this idea to its logical extreme and says: what if we treat the context itself as an evolving, self-improving artifact?
The Two Big Problems ACE Identifies
Before we get to how ACE works, its worth understanding the two failure modes it diagnoses in existing context adaptation methods. These are genuinly interesting observations.
A. Brevity Bias
When you ask an LLM to optimize or rewrite a prompt, it has a natural tendancy to make things shorter. This sounds fine on the surface — conciseness is generally good right? But the problem is that LLMs will drop domain-specific insights and detailed strategies in favor of generic, compact instructions. The optimized prompt "looks" cleaner but actually performs worse because its lost the detailed knowledge that made it useful.
This is a really underappreciated problem. If you've ever used a prompt optimizer like DSPy's MIPROv2 or GEPA, you may have noticed this — the optimized output reads well but somtimes seems to have lost the soul of what you were trying to say.
B. Context Collapse
This ones even more insidious. When you do iterative context rewriting — where you take a context, run it, get feedback, then rewrite the whole thing — each rewrite cycle tends to erode details. The context gets progressivly more generic over multiple iterations. The authors call this "context collapse" and they observed it specifically when testing Dynamic Cheatsheet on the AppWorld benchmark.
Its basicly like a game of telephone but with prompts. Each time you pass the context through an LLM rewriter, you loose a little bit of signal. Do it enough times and you end up with something thats technically a valid prompt but has been stripped of all the useful domain knowlege.
How ACE Actually Works
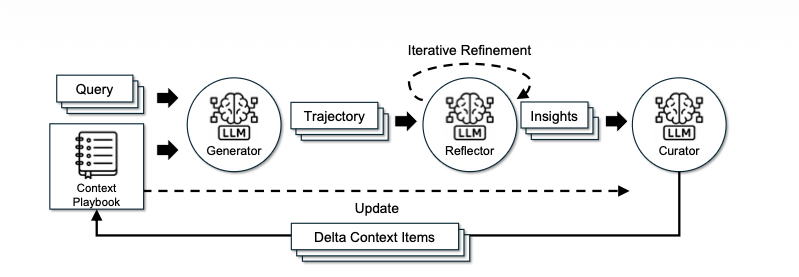
The ACE framework has three main components that work together: a Generator, a Reflector, and a Curator. Heres the rough flow:
The Generator takes the current context (which they call a "playbook") and uses it to solve new problems. Think of this as your agent or reasoning system actualy doing its job with whatever instructions it currently has.
The Reflector then looks at what happned — did the solution work? did it fail? why? — and produces "delta entries." These are small, incremental additions or modifications to the existing playbook. This is the critical innovation. Instead of rewriting the whole context from scrach, you just produce little updates.
The Curator periodically reorganizes and cleans up the playbook. Merging duplicate entries, removing contraditions, keeping things structured. Think of it like a librarian who ocasionally tidies the shelves.
The Delta Update Trick
This is honestly the thing that makes the whole system work, and its also the biggest lesson of the paper. Instead of doing monolithic rewrites of your context (which causes both brevity bias and context collapse), ACE uses incremental delta updates. The context is structured as a collection of itemized bullets, each with metadata and content. When the system learns something new, it adds or modifies specific bullets rather than regenerating everthing.
This has three nice propertys:
- Localization — only the relevant parts get updated
- 2. Fine-grained retrieval — you can find specific pieces of knowledge
- 3. Incremental adaptation — the context grows organicaly over time without loosing what it already knows
Grow and Refine
The other clever bit is the "grow-and-refine" strategy. The system alternates between growing the context (adding new insights from new experiences) and refining it (consolidating, deduplicating, and cleaning up). This prevents the playbook from getting bloated with redundent information while still allowing it to accumulate knowlege over time.
The Results That Made Me Do a Double-Take
OK, so heres where it gets really interesting. The numbers are genuinly impressive.
On the AppWorld agent benchmark (which tests agents on API calls, code generation, and environment interaction), ACE improved performance by 10.6% over baselines on average. On financial analysis benchmarks (FiNER and Formula — these are XBRL-based financial reasoning tasks), it improved by 8.6%.
But the number that really caught my attention: on the AppWorld leaderboard, ACE using DeepSeek-V3 (an open source model) matched the top-ranked production-level agent from IBM called CUGA on overall average, and actually surpassed it on the harder test-challenge split. Let that sink in — a self improving context system with a smaller open-source model competeing with and beating production-level agents that presumably have way more engineering effort behind them.
And the kicker? ACE worked without any labeled supervision. It doesnt need ground-truth answers to improve. It learns from natural execution feedback — basically just by observing whether its actions succeeded or failed. This is huge for practical applications because getting labeled data is expensive and sometimes just not feasable.
The Cost Story
Theres also a compelling cost angle. Compared to GEPA (a popular prompt optimizer), ACE reduced offline adaptation latency by 82.3% on AppWorld and needed 75.1% fewer rollouts. Compared to Dynamic Cheatsheet for online adaptation on FiNER, it cut latency by 91.5% and token costs by 83.6%.
You might think "well longer contexts mean higher serving costs" but the paper makes a good point about this. Modern inference systems use KV-cache compression and prefix caching. So once you've computed the KV cache for your playbook, serving it is relativley cheap. The context adaptation cost (the one-time cost of actually building the playbook) is where the savings matter, and ACE crushs it.
The Actual Biggest Lesson
So what is the biggest lesson here? I think its this:
We've been over-indexing on model-level improvements and under-investing in context engineering.
Fine-tuning is expensive, brittle, and hard to iterate on. You need labeled data, you need GPUs, you need to worry about catastrophic forgetting, and every time the base model updates you might need to redo your fine-tuning. Context engineering, on the other hand, is interpretable (you can read it), portable (works across models), cheap to update (no GPU needed), and composes naturally with other techniques like RAG.
ACE takes this further and shows that contexts dont even need to be static. They can evolve and self-improve through use, accumulating domain expertise over time. The playbook your system uses after 1000 interactions is fundamentaly different from — and much better than — the one it started with. And you didnt need to retrain anything.
This maps really well to how human expertise works, actualy. A senior engineer doesnt have fundamentally different brain hardware than a junior one. They have better mental models, better heuristics, better pattern recognition — all of which lives in their "context" not their "weights."
What This Means for Practitioners
If you're building LLM applications today, heres what I'd take away from this paper:
First, invest more time in your system prompts and context. Don't just write a paragraph and call it a day. Structure your context with specific, detailed, domain-specific strategies. Make it more like a comprehensive playbook than a brief instruction.
Second, think about how your context can evolve over time. Even if you dont implement the full ACE framework, the basic idea of collecting failure cases, reflecting on what went wrong, and adding specific tips to your system prompt is incredibily powerful. Its basicly what good engineering teams do manually anyway — but ACE shows you can automate it.
Third, consider the delta-update mindset. When you update your prompts, don't rewrite them from scratch each time. Add specific items, modify specific sections, keep a running log of what works. This preserves institutional knowledge rather then overwriting it.
And fourth, dont assume you need a bigger model. The results on AppWorld show that good context engineering with a capable open source model can match or beat production systems built on top of presumably larger, more expensive models. The context is the multiplier.
Wrapping Up
The ACE paper reinforces something I've been feeling for a while now: we're entering the era of context engineering. The model is a commodity — or at least its becoming one. The real competitive advantage is in how you engineer the information that surrounds your queries. How you accumulate domain knowledge, how you structure it, how you keep it fresh and relevant.
Stop obssesing over which model to use. Start obsessing over what you put in the context window.
The paper is at arxiv.org/abs/2510.04618 if you want to dig into the details yourself. Its a genuinley well-written paper with clear results, which is always refreshing.