Why DeepSeek-OCR 2 Could Change Document AI Forever

Yesterday, DeepSeek dropped a paper that might quietly reshape how machines read documents. It's called DeepSeek-OCR 2: Visual Causal Flow, and if you work anywhere near document processing, OCR, or enterprise AI — pay attention.
The Problem Nobody Talks About
Every vision-language model today reads images the same way: left to right, top to bottom. Pixel by pixel. Row by row. Like a typewriter scanning a photograph.
For a photo of a dog? That's fine. For a complex business document with headers, columns, tables, footnotes, and sidebars? It's a disaster.
Think about how you actually read a document. You don't start at the top-left pixel and scan across. You look at the title first. Then the headers. Your eyes jump to the relevant section. You skip the sidebar. You follow the logical flow of information, not the physical layout of pixels.
Current AI can't do that. It processes visual "tokens" (small image patches) in a rigid raster-scan order with fixed positional encoding. The model has to spend enormous effort just figuring out what order things should be read in — before it even starts understanding the content.
This is why document AI still struggles with multi-column layouts, complex tables, and mixed-format pages despite billion-parameter models being thrown at the problem.
What DeepSeek-OCR 2 Actually Does
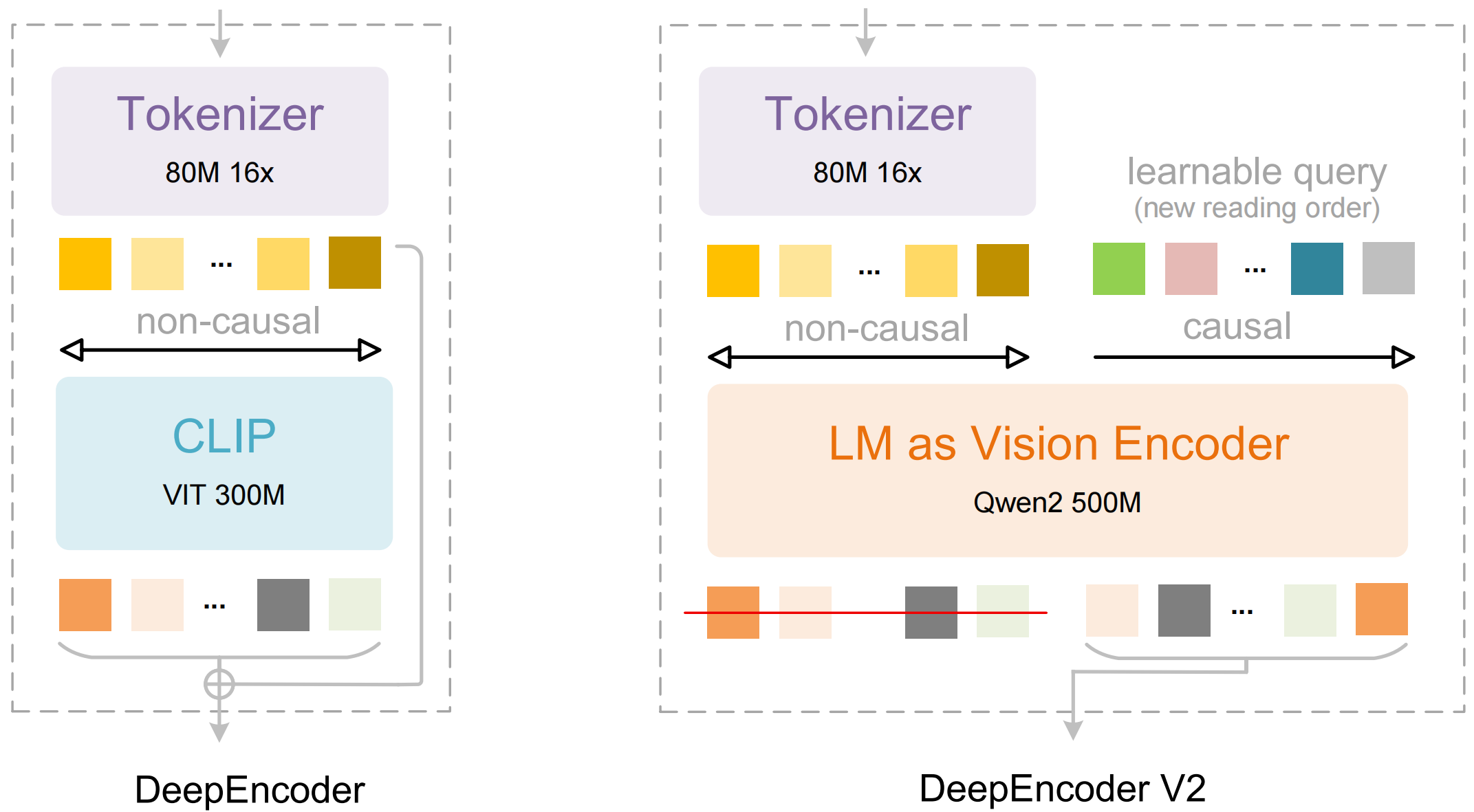
The core innovation is a new encoder called DeepEncoder V2. Instead of using the standard Vision Transformer (ViT) approach of fixed-order patch processing, it replaces the encoder with something fundamentally different: a language model (Qwen2-0.5B) that dynamically reorders visual tokens based on what's actually in the image.
They call this Visual Causal Flow.
Here's how it works:
- Visual tokens get bidirectional attention — the image patches can all see each other, just like in a standard ViT. Nothing new here.
- Learnable "causal flow queries" process them with causal attention — these queries work like an LLM decoder. Each query can see all the visual tokens AND all previous queries, but not future queries. This creates a sequential, semantic ordering.
- The reordered tokens feed into the main LLM — which then does autoregressive reasoning over a sequence that's already in the right order.
Two cascaded 1D causal reasoning steps to achieve genuine 2D understanding. That's the paradigm shift.
Why This Changes the Game for Document AI
1. It actually understands document structure, not just pixels.
The model learns reading order from the content itself. Headers get read before body text. Table cells follow logical row/column order. Multi-column layouts get parsed correctly — not because someone hard-coded rules, but because the encoder learned the causal flow of information.
Their reading order accuracy improved significantly: edit distance dropped from 0.085 to 0.057 compared to DeepSeek-OCR 1. That's a 33% improvement in understanding how documents should be read.
2. It's dramatically more efficient.
DeepSeek-OCR 2 uses only 256 to 1,120 visual tokens. Compare that to models like InternVL3 that use 6,000-7,000+ tokens for the same task. Fewer tokens means faster inference, lower costs, and the ability to process longer documents.
For enterprise document processing where you're running millions of pages through a pipeline, this efficiency difference is the gap between "interesting research" and "actually deployable."
3. The results speak for themselves.
On OmniDocBench v1.5 — the most comprehensive document understanding benchmark available — DeepSeek-OCR 2 scores 91.09%. That's state of the art. It beats Qwen3-VL-235B (a model orders of magnitude larger), Gemini-2.5 Pro, and GPT-4o.
Production repetition rate (a common failure mode where models repeat text) dropped from 6.25% to 4.17%. That matters when you need reliable output at scale.
4. It opens a new architectural paradigm.
This is the part that excites me most. The "Visual Causal Flow" concept isn't limited to documents. The paper hints at a future where images, audio, and text all get processed through the same unified architecture — each with their own causal flow queries that reorder raw input into semantically meaningful sequences before the LLM reasons over them.
If this paradigm holds, we might be looking at the beginning of the end for specialized encoders entirely. One architecture to rule them all, with modality-specific queries doing the heavy lifting.
What This Means for Businesses
If your business processes documents at any scale — invoices, contracts, medical records, financial reports, legal filings — this matters to you. Not today, necessarily. The model was just published. But the direction is clear:
- Document processing accuracy is about to take a leap. Not incremental improvement. Architectural breakthrough.
- Costs will drop. Fewer tokens per document means cheaper processing at scale.
- Complex layouts will finally work. The documents that current AI chokes on — multi-column, mixed tables, nested structures — are exactly where this approach shines.
- The gap between human reading and machine reading is closing. For the first time, the encoder is trying to read like we do — semantically, not spatially.
We've been building document AI workflows for clients and this is the kind of foundational shift that changes what's possible. If you're evaluating document automation, the timing just got very interesting.
The Bottom Line
DeepSeek-OCR 2 isn't just a better OCR model. It's a different way of thinking about how machines should process visual information. By giving the encoder the ability to reason about reading order — to create a "causal flow" through visual content — they've addressed one of the most fundamental limitations in how VLMs handle structured documents.
The code and model weights are open source. The paper is on arXiv. And if the results hold up in production environments, Document AI just entered a new era.
Softmax Data builds AI agents and document automation for businesses. If you're exploring what AI can do for your document workflows, let's talk.